최신 NLP 모델 비교(GPT, BERT, RoBERTa, ELECTRA)
- 1 minModel 비교
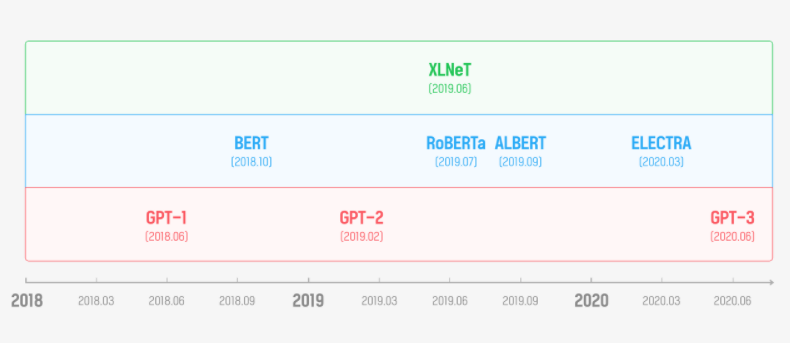
- GPT Generative Pre-trained Transformer
- Transformer base의 최초 논문
- 이전 단어를 바탕으로 다음 단어를 예측하는 방법으로 훈련된다.
- 문맥파악에 약점이 있다.
-
BERT **Bidirectional Encoder Representations from Transformers**
: Nest Sentence prediction을 바탕으로 자연스럽게 문맥을 파악할 수 있다.
- Masked 된 단어를 예측하는 양방향 (문맥) 바탕 예측으로 훈련된다.
- NSP를 도입하여 문장간의 관계도 학습할 수 있다.
- Bert 기반 모델
-
RoBERTa(19년) - FaceBook **A Robustly Optimized BERT Pretraining Approach**
→ 단방향 학습인 GPT가 Parameter 수와 학습데이터를 늘리자 좋은 성능? 왜?
- Bert의 고정된 Mask로 반복 학습 → Dynamic Masking 도입
- 두 문장간의 예측이 의미가 있을까? → NSP 제거
- 학습데이터 16G → 학습데이터 160G
-
**ALBERT(19년) A Little BERT** for Self-supervised Learning of Language Representations
NSP → SOP(Sentence order prediction)으로 학습
Transformer 구조 개선 → 모델사이즈 감소
-
ELECTRA(20년)
**Pre-training Text Encoders as Discriminators Rather Than Generators**
MLM(Masked Language Model)을 개선시킨 RTD(Replaced Token Detection)
-
이해를 위한 이미지
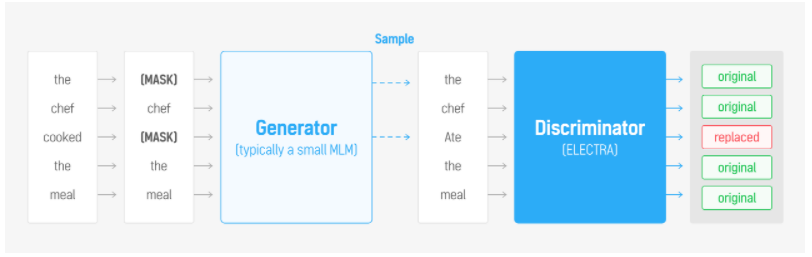
[MASK] 토큰을 작은 Generator로 생성하고 Discriminator로 가짜 토큰인지 아닌지 판별하는 방식으로 학습한다.
효과 ? BERT는 [MASK] 토큰에 대해서만 학습하지만 ELECTRA는 모든 토큰에 대해서 학습할 수 있어 효율적인 학습이 된다.
-
-
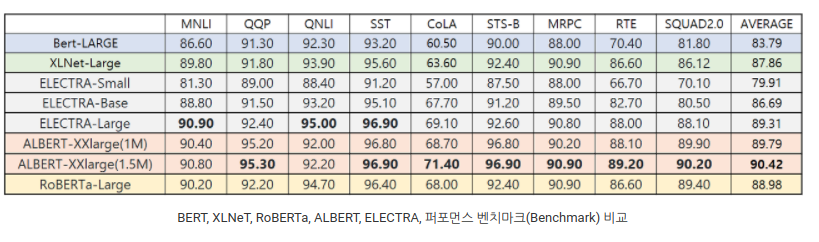
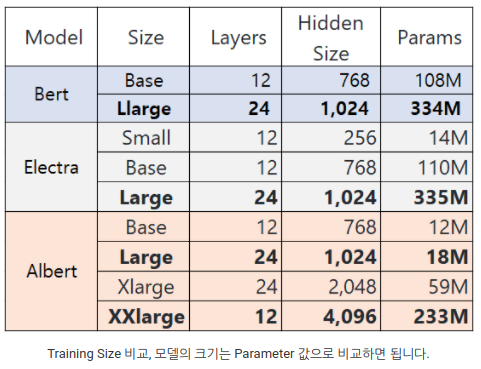
- Pretrained Model의 목표
- Model downsizing: 모델의 크기가 너무 커서 메모리에 들어가지 못한다.
- Train Resource downsizing: 학습이 오래걸린다.
- Memory degradation: 모델에 따라 일정 수준이상 복잡해지면 모델 성능이 떨어진다