Xilinx FPGA tutorial
- 7 minsFPGA 튜토리얼 정리이다.
Feature tutorial과 Design tutorial로 나눠져 있다.
Feature tutorial은 Specific features or flows of Vitis를 배운다
Design tutorials은 higher-level concepts or design flows, walk through specific examples or reference designs and more and complex designs or applications
Feature tutorial은 크게 얻을 수 있는게 많이 없고, Vitis를 잘 사용하는 법을 얻을 수 있었다.
이번 포스트에서는 Design tutorial을 중점으로 진행한다.
먼저 software 구현 (CPU)로 구현한 성능 측정 결과는 다음과 같다. 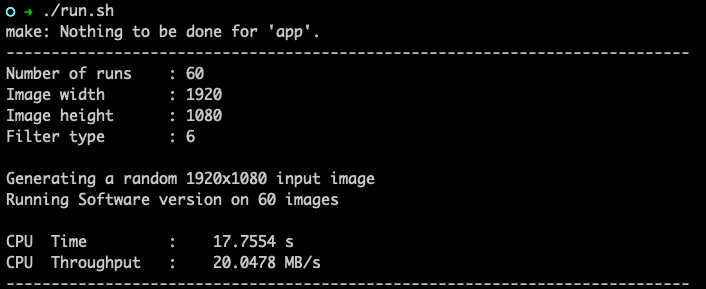
먼저 hardware 구현 (FPGA)로 구현한 성능 측정 결과는 다음과 같다.
먼저 Task에 대해 이해해볼 것이다. 바로 2D video convolution filter로
Video Resolution = 1920 x 1080
Frame Rate (FPS) = 60
Pixel Depth (Bits) = 8
Color Channels(YUV) = 3
Minimum Throughput = 1920 * 1080 * 60 * 8 * 3 = 378MB/s
최소한 378MB/s의 출력량이 필요하다는 것을 알 수 있다. 하지만 이는 SW(CPU)결과에 비하면 요구량이 초과되는 것을 확인할 수 있다.
Hardware implementation
Convolution 연산의 특징에 대해 더 생각해보아야한다. four-level nested loop이고, output pixel 결과값을 기준으로 병렬적으로 수행할 수 있다.
filter size가 15x15이기 때문에 inner two loop의 경우 dot product 연산이고, 하나의 output pixel 당 225 MAC operations이 필요하다.
MACs per Cyle = 1 이라고 가정할때 Hardware Fmax(MHz) = 300 Throughput = freq. / #mac ops = 300/225 = 1.33 (MPixels/s) = 1.33MB/s
따라서 우리는 이 1.33MB/s 를 가지고 병렬화를 하면된다.
첫번째 optimization은 loop unrolling이다. loop unrolling을 통해 연산을 동시에 수행할 수 있다. 따라서 두개의 inner loop에 unrolling을 적용하면 15*15=225배의 속도향상을 얻을 수 있다.
하지만 memory bandwidth를 확인해보면
Input memory bandwidth = Fmax * Input pixels read per output pixel = 300 * 225 = 67.5 GB/s
하지만 실제로 확인해보면 convolution의 input은 서로 다른 pixel이 아니라 입력이 중복되기 때문에 실제로 그렇지는 않다.
Vector addition 코드 분석
FPGA로 전달되는 코드들은 align이 필요하다. 따라서 사용되는 코드는 다음과 같은데
template <typename T>
struct aligned_allocator
{
using value_type = T;
T* allocate(std::size_t num)
{
void* ptr = nullptr;
if (posix_memalign(&ptr,4096,num*sizeof(T)))
throw std::bad_alloc();
return reinterpret_cast<T*>(ptr);
}
void deallocate(T* p, std::size_t num)
{
free(p);
}
}
하나 하나 차근 차근 분석해보면,
posix_memalign첫번째 인자
ptr할당된 메모리 블락의 시작주소를 의미한다.두번째 인자는 요구되는 메모리 블록의 정렬값이고, 이는 바이트 단위이므로 주의한다. 당연히 2의 거듭제곱으로 지정해야한다.
세번째 인자는 할당할 메모리 블록의 크기를 의미한다.
리턴 값의 경우 메모리 할당에 실패하면 0이므로 이를 잘 처리해주는것도 중요하다.
reinterpret_cast이는
posix_memalign로 할당된 메모리 주소공간을 원하는 타입으로 강제로 변환하는 것이다. align을 지켜 할당받은 메모리 주소공간은 따로 자료형이 없기 때문에 형변환 종류를 명시해주면 더 안전한 코딩이 될 수 있다.
위와 같이 custom align allocator를 작성해주면 vector 컨테이너에 대해 custom allocator를 지정해줄 수 있다.
vector <float, align_allocater<float>> vec1(DATA_SIZE, 10)
vector container의 초기화에 2개의 값을 넣는 것은 특별한 건 아니고, 10으로 initialize 하는 것이다.
cl::Buffer 로 Device의 memory를 allocation할 수 있다. vector container의 .data() 메소드는 vector 컨테이너의 주소값을 리턴해주는 함수이다. host_ptr를 넘겨주는 이유는 CL_MEM_USE_HOST_PTR가 설정되어 있어야한다.
setArg()를 지정해 준 후 enqueueMigrateMemObject를 수행하면 global memory 공간에 pinned memory를 생성해놓을 수 있다고 한다.
enqueueWriteBuffer ( const Buffer & buffer,
cl_bool blocking,
size_type offset,
size_type size,
const void * ptr,
const vector< Event > * events = NULL,
Event * event = NULL
)
enqueueWriteBuffer는 global memory에 실질적인 입력을 수행한다. blocking 옵션에는 CL_TRUE, CL_FALSE 두가지 선택지가 있다. CL_TRUE의 경우가 blocking을 포함한다. CL_FALSE를 사용하고 싶다면 event에 인자를 넣어줘야한다.
event 객체가 이해하기 가장 어려운 것 같다. 이때 주의해야할 것은 non-blocking으로 수행하면 OpenCL은 순차적인 실행을 보장하지 않는다는 것이다. 이를 위해 enqueue 계열의 함수들을 보면 event 객체를 담고 있는 vector container를 입력으로 받는것을 확인할 수 있는데 이는 vector container 내에 들어있는 event 객체들이 끝날때까지 기다린 후 수행한다는 의미이다.
HLS pragma에 대하여
pragma interface
HLS가 합성될때 함수의 argument는 RTL port로 합성된다.
#pragma HLS interface mode=<mode> port=<name> [OPTIONS]
모드에는 크게 3가지가 있다.
- Port-Level Protocols
- AXI Interface Protocols
- Block-level Protocols
Vector addition example에서는 2번 AXI interface protocol에 해당하는 s_axilite, m_axi밖에 사용하지 않았다. m_axi는 AXI4 interface를 사용한다는 의미이고, s_axilite는 AXI4-Lite interface를 사용한다는 의미이다. AXI는 Advanced eXtensibile Interface의 약자로 ARM에서 개발한 버스 프로토콜이다. AXI4는 out-of-order 데이터 전송, burst 전송 등 다양한 기능을 제공한다. 간단한 디자인을 위해선 AXI4-Lite, 복잡한 구현에 있어서는 AXI4를 사용해야한다.
AXI Stream은 말 그로 ADC, DAC, 비디오 처럼 스트리밍 하는데에 적합하게 최적화 되어 있다.
AXI는 총 5개의 Channel로 구성되어 있고 각 채널은 독립적으로 동작한다.
#pragma HLS INTERFACE m_axi offset=SLAVE bundle=gmem port=a max_read_burst_length = 256
#pragma HLS INTERFACE m_axi offset=SLAVE bundle=gmem port=b max_read_burst_length = 256
#pragma HLS INTERFACE m_axi offset=SLAVE bundle=gmem1 port=c max_write_burst_length = 256
#pragma HLS INTERFACE s_axilite port=a bundle=control
#pragma HLS INTERFACE s_axilite port=b bundle=control
#pragma HLS INTERFACE s_axilite port=c bundle=control
#pragma HLS INTERFACE s_axilite port=n_elements bundle=control
#pragma HLS INTERFACE s_axilite port=return bundle=control
AXI 채널의 종류를 이해하면 왜 이렇게 pragma를 사용하는지 알 수 있다. m_axi는 AXI interface이므로 memory burst를 지원한다. 따라서 port a, b, c 에 대해 interface를 지정한다. 그리고 추가로 AXI4-lite를 활용해 control signal을 수행할 것을 같은 argument에 대해 지정한다.
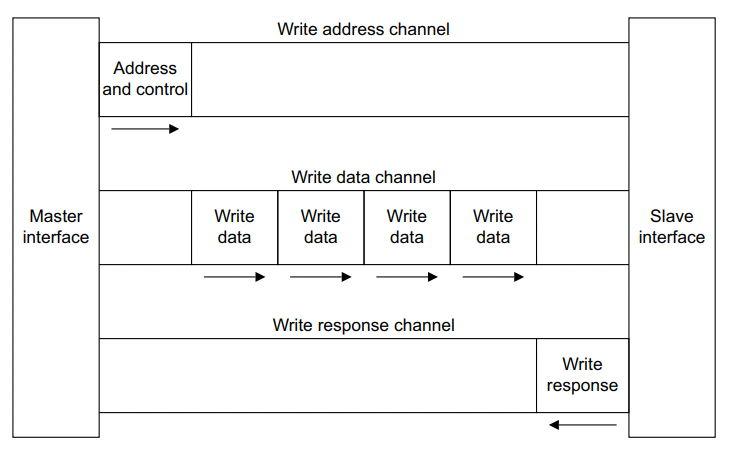
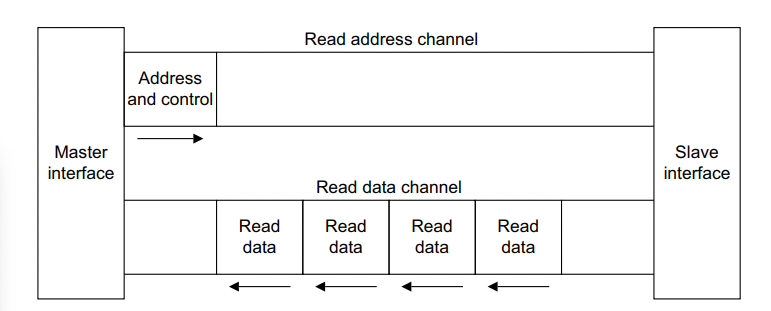
읽기 쓰기에는 control signal이 필요하다. Write의 경우 데이터가 잘 전송되었는지 Host(Master)에서 확인할 필요가 있으므로 추가적인 response가 오고가는 channel이 존재한다.
포트에는 function argument의 이름을 넣어주면 된다. bundle의 이름은 자유롭게 정해도 되는데 bundle로 묶어주는 단위는 각각 하나의 interface를 공유한다. 따라서 현재 vector addition의 예제에서는 특히 input 두개를 서로 다른 bundle로 나눠주는것이 생각보다 중요하다. interface하나로는 한개의 data channel을 가지기 때문이다.
v++라는 컴파일러를 사용해 생성할 수 있는 결과물은 다음과 같다.
-
.xo파일:(Xilinx Object) v++ 컴파일러가 생성하는 중간 바이너리 파일로 C++파일로 작성된 FPGA 커널 디자인의 컴파일된 형태, FPGA 디자인의 논리회로 구현을 설명하는 특정한 형식으로 되어있다. -
.xclbin파일: (Xilinx Binary) 이 파일이 최종적으로 FPGA 디바이스에 로드되어 실행된다.
FPGA의 꽃 DATAFLOW와 hls::stream
미쳤다… HLS는 DATAFLOW와 stream을 이해했는지 안했는지로 나뉠 수 있을 것 같다.
#pragma HLS dataflow
read_data(...)
compute(...)
write(...)
pragma는 사전적으로 만능이라는 의미이다. 전처리 구문 중 하나로 컴파일러에 종속적인 구문이다.
컴파일러에게 부탁하는 요소를 작성하면 컴파일러가 알아서 이를 고려하여 코드를 refactoring해준다.
FPGA의 dataflow pragma는 아래의 top function들을 모두 병렬적으로 수행할 수 있게 해준다. 단순히 들었을때는 크게 쓸모 없는 기능이라고 할 수 있다. 왜냐하면 그렇게 완전 병렬화 할 수 있는 task는 많이 존재하지 않기 때문이다. 하지만 hls::stream와 함꼐 사용되면 달라진다. 이 stream 은 FIFO buffer라고 생각하면 된다. 이 stream 데이터가 차있는지를 바탕으로 HLS dataflow의 top function들은 수행을 멈추고 기다린다. 이 stream이 top function들의 수행에 flow를 유지하는 역할을 하므로 꼭 call by reference로 전달하여 hls::stream에 대해서 destructor가 수행되지 않도록 주의해야한다.
Extern “C”
c++ 소스에서 선언한 전역 변수나 함수를 C에서 사용해야할 때 사용된다. 왜냐하면 gcc와 g++가 컴파일 후 함수 명이 크게 다르기 때문이다. gcc의 경우 함수 이름이 거의 그대로 유지되지만, g++의 경우 함수 이름이 복잡한 이름으로 변경된다. 왜냐하면 c++ 에서는 함수 오버로딩이라는 기능이 있기 때문에, 같은 함수명이라도 전달받는 타입이 다르면 다른 함수를 가르키게 된다. 이때문에 C와 C++간의 차이가 있고, 이를 Name Mangling이라고 한다. (심하게 훼손하다)